
1) Partitioned Outer Join
I would like to start with PARTITIONED OUTER JOIN. Because it is one of the least used feature. Suppose that you have two basic tables that represent the course hours of instructors, these courses starts at between 9:00 and 15:00 o’clock and every course takes an hour. You can see the contents of the tables as shown below.
create table t_tutor_schedule
(
instructor varchar2(100),
course varchar2(100),
start_time interval day(0) to second(0),
end_time interval day(0) to second(0)
);
insert into t_tutor_schedule values('Connor McDonald', 'Advanced PL/SQL programming', to_dsinterval('0 10:00:00'), to_dsinterval('0 11:00:00'));
insert into t_tutor_schedule values('Connor McDonald', 'SQL tunning', to_dsinterval('0 13:00:00'), to_dsinterval('0 14:00:00'));
insert into t_tutor_schedule values('Connor McDonald', 'Oracle Architecture', to_dsinterval('0 14:00:00'), to_dsinterval('0 15:00:00'));
insert into t_tutor_schedule values('Maria Colgan', 'Optimizer statistics', to_dsinterval('0 09:00:00'), to_dsinterval('0 10:00:00'));
insert into t_tutor_schedule values('Maria Colgan', 'SQL fundamentals', to_dsinterval('0 10:00:00'), to_dsinterval('0 11:00:00'));
insert into t_tutor_schedule values('Maria Colgan', 'Database In-Memory and Indexes', to_dsinterval('0 13:00:00'), to_dsinterval('0 14:00:00'));
insert into t_tutor_schedule values('Maria Colgan', 'JSON in Oracle database', to_dsinterval('0 14:00:00'), to_dsinterval('0 15:00:00'));
commit;
create table t_course_hours
as
select
numtodsinterval( to_date(to_char(sysdate, 'dd/mm/yyyy') || '08:00:00', 'dd/mm/yyyy hh24:mi:ss') + level/24 - trunc(sysdate), 'day' ) hours
from dual connect by level <= 7;
SELECT * FROM t_tutor_schedule;
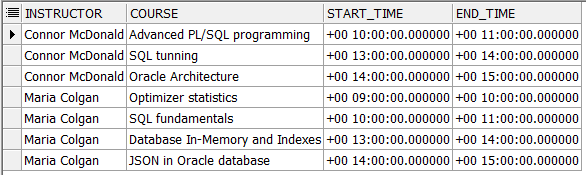
SELECT * FROM t_course_hours;

You want to show the full schedule of each instructor whether he or she has lesson or not. In other words, you want to see the whole day schedule even if there is not any course for a specific hour. You need to include gaps too. So, you want to generate the following diagram.
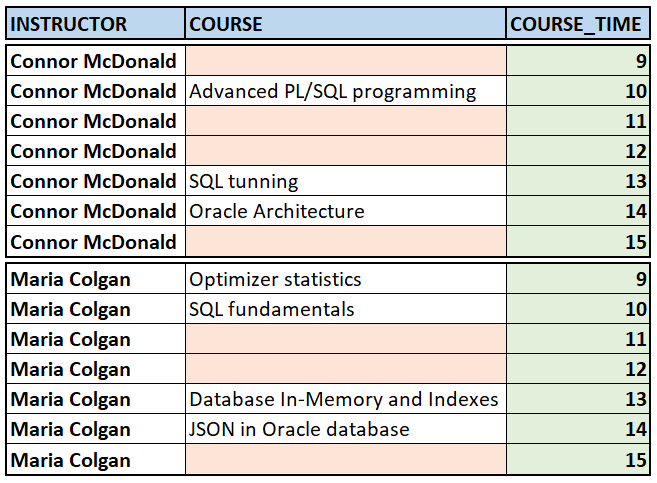
You might think that you can achieve this with FULL OUTER JOIN. However, it cannot meet exactly what you want.
SELECT
t.instructor, t.course, EXTRACT(HOUR FROM (h.hours)) course_time
FROM t_tutor_schedule t FULL OUTER JOIN t_course_hours h on t.START_TIME = h.HOURS
ORDER BY instructor, course_time;

Let’s use PARTITION BY clause in order to get the intended result.
SELECT
t.instructor, t.course, EXTRACT(HOUR FROM (h.hours)) course_time
FROM t_tutor_schedule t
PARTITION BY (instructor)
RIGHT JOIN t_course_hours h ON t.START_TIME = h.HOURS
ORDER BY instructor, course_time;

2) REGEXP_LIKE
The first example that comes to my mind for REGEXP_LIKE is that it helps to reduce the usage of LIKE condition in the WHERE clause. Especially, If you need to use multiple values with LIKE condition. Than, REGEXP_LIKE can be a savior for you. Let’s say you have a table with user comments and a word list table. You want to filter the comments which contain undesired words. In that word list table what if it has thousands of rows. Surely, you don’t want to write thousands of LIKE conditions for all of these words separately as in the example below.
SELECT * FROM T_COMMENTS
WHERE
TXT NOT LIKE '%unwanted_word_1%' AND
TXT NOT LIKE '%unwanted_word_2%' AND
TXT NOT LIKE '%unwanted_word_3%' AND
TXT NOT LIKE '%unwanted_word_4%' AND
TXT NOT LIKE '%unwanted_word_5%' AND
TXT NOT LIKE '%unwanted_word_6%' AND
TXT NOT LIKE '%unwanted_word_7%' AND
TXT NOT LIKE '%unwanted_word_8%' AND
TXT NOT LIKE '%unwanted_word_9%' AND
TXT NOT LIKE '%unwanted_word_10%' AND
.....
TXT NOT LIKE '%unwanted_word_1000%';
Bear in mind that regular expressions are CPU intensive. It is really powerful processes. However computationally expensive. So, use it only when you absolutely have to.
You can use the following query instead.
SELECT * FROM
T_COMMENTS UC,
(
SELECT
LISTAGG(UNWANTED_WORD, '|') WITHIN GROUP(ORDER BY NULL) WORDS --Arranging the right pattern
FROM T_WORD_LIST
) WL
WHERE NOT REGEXP_LIKE (UC.TXT, WL.WORDS);
If the number of words you want to filter is not many, you can also use it as follows.
SELECT * FROM T_COMMENTS
WHERE NOT REGEXP_LIKE (TXT, 'unwanted_word_1|unwanted_word_2|unwanted_word_3');
3) Generating desired amount of rows
You can generate rows on the fly. There are multiple ways for this. In the following examples, number sequences are generated from 1 to 10.
--Hierarchical query
SELECT LEVEL FROM DUAL CONNECT BY LEVEL <= 10;
--Subquery factoring
WITH
Q1(N) AS
(
SELECT 1 FROM DUAL
UNION ALL
SELECT N+1 FROM Q1 WHERE N < 10
)
SELECT * FROM Q1;
--XAMTABLE
SELECT ROWNUM FROM XMLTABLE('1 to 10');
--Model clause
SELECT V
FROM DUAL
MODEL DIMENSION BY (0 R)
MEASURES (0 V)
RULES ITERATE (10) (
V[ITERATION_NUMBER] = ITERATION_NUMBER + 1
)
ORDER BY 1;
Let’s compare the runtimes between them for 500k rows. The comparison has been performed in Oracle 19C.
DECLARE
V_START NUMBER;
PROCEDURE SHOW_ELAPSED_TIME(P_NAME VARCHAR2)
IS
BEGIN
DBMS_OUTPUT.PUT_LINE(P_NAME||' elapsed time: '||TO_CHAR((DBMS_UTILITY.GET_TIME - V_START)/100, '00.00'));
V_START := DBMS_UTILITY.GET_TIME;
END;
BEGIN
V_START := DBMS_UTILITY.GET_TIME;
FOR I IN (SELECT LEVEL FROM DUAL CONNECT BY LEVEL < 500000)
LOOP
NULL;
END LOOP;
SHOW_ELAPSED_TIME('Hierarchical query');
FOR I IN (
WITH
Q1(N) AS
(
SELECT 1 FROM DUAL
UNION ALL
SELECT N+1 FROM Q1 WHERE N < 500000
)
SELECT * FROM Q1
)
LOOP
NULL;
END LOOP;
SHOW_ELAPSED_TIME('Subquery factoring');
FOR I IN (SELECT ROWNUM FROM XMLTABLE('1 to 500000'))
LOOP
NULL;
END LOOP;
SHOW_ELAPSED_TIME('XAMTABLE');
FOR I IN (
SELECT V
FROM DUAL
MODEL DIMENSION BY (0 R)
MEASURES (0 V)
RULES ITERATE (500000) (
V[ITERATION_NUMBER] = ITERATION_NUMBER + 1
)
ORDER BY 1
)
LOOP
NULL;
END LOOP;
SHOW_ELAPSED_TIME('Model clause');
END;
Hierarchical query elapsed time: 00.28
Subquery factoring elapsed time: 01.99
XAMTABLE elapsed time: 00.31
Model clause elapsed time: 41.40
As it can be seen from the results, CONNECT BY clause is more efficient than the others. Moreover, you can also generate random various characters as in the example below.
SELECT
DBMS_RANDOM.RANDOM, --Integer
DBMS_RANDOM.VALUE, --Between 0 and 1
DBMS_RANDOM.VALUE(1, 100), --Numbers in the given range. In this Example, between 1 and 100
DBMS_RANDOM.STRING('U', 10), --Uppercase alpha character
DBMS_RANDOM.STRING('L', 10), --Lowercase alpha character
DBMS_RANDOM.STRING('A', 10), --Mixed case alpha character
DBMS_RANDOM.STRING('X', 10), --Uppercase alpha-numeric characters
DBMS_RANDOM.STRING('P', 10), --Any printable characters
TRUNC(SYSDATE + DBMS_RANDOM.VALUE(0, 366)) --Adds to the current date as many days as produced in a given interval
FROM DUAL;
4) Oracle defined collections
You can use Oracle’s built-in collection types. Although it is not used much, it can make your job easier in some places. Some of the system defined types are listed below. If you look at the script of ODCI built-in collections, you will see that they are VARRAY types. In addition, if you want to use associative arrays you can use DBMS_SQL package.
- sys.ODCIDateList
- sys.ODCINumberList
- sys.ODCIRawList
- sys.ODCIVarchar2List
SELECT * FROM TABLE(SYS.ODCINUMBERLIST(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));

SELECT * FROM TABLE(SYS.ODCIVARCHAR2LIST('a', 'b', 'c', 'd', 'e'));

DECLARE
ARR1 SYS.ODCINUMBERLIST;
ARR2 DBMS_SQL.NUMBER_TABLE;
BEGIN
ARR1 := SYS.ODCINUMBERLIST(1, 3, 5, 7, 9);
FOR IND IN ARR1.FIRST..ARR1.LAST
LOOP
DBMS_OUTPUT.PUT_LINE(ARR1(IND));
END LOOP;
ARR2(1) := 1;
ARR2(2) := 3;
ARR2(3) := 5;
ARR2(4) := 7;
ARR2(5) := 9;
FOR IND IN ARR2.FIRST..ARR2.LAST
LOOP
DBMS_OUTPUT.PUT_LINE(ARR2(IND));
END LOOP;
END;
Besides, ALL_COLL_TYPES dictionary view can be used in order to see all system defined VARRAYs and nested tables. (DBMS_DEBUG_VC2COLL, ORA_MINING_NUMBER_NT, ORA_MINING_VARCHAR2_NT are some of the useful collections.)
SELECT
COLL_TYPE, ELEM_TYPE_NAME, TYPE_NAME, LENGTH, UPPER_BOUND
FROM ALL_COLL_TYPES
WHERE OWNER = 'SYS' AND ELEM_TYPE_NAME IN ('VARCHAR2', 'NUMBER', 'DATE', 'CLOB')
ORDER BY COLL_TYPE, ELEM_TYPE_NAME, TYPE_NAME;
You can also use MULTISET operators with nested tables.
DECLARE
ARR_NT1 sys.ORA_MINING_NUMBER_NT := sys.ORA_MINING_NUMBER_NT(1, 2, 3, 4, 5);
ARR_NT2 sys.ORA_MINING_NUMBER_NT := sys.ORA_MINING_NUMBER_NT(1, 2, 3, 8, 9);
ARR_NT3 sys.ORA_MINING_NUMBER_NT;
BEGIN
--Merge
ARR_NT3 := ARR_NT1 MULTISET UNION ARR_NT2; --1, 2, 3, 4, 5, 1, 2, 3, 8, 9
--Merge distinct
ARR_NT3 := ARR_NT1 MULTISET UNION DISTINCT ARR_NT2; --1 2 3 4 5 8 9
--Minus
ARR_NT3 := ARR_NT1 MULTISET EXCEPT ARR_NT2; --4, 5
--Intersect
ARR_NT3 := ARR_NT1 MULTISET INTERSECT ARR_NT2; --1, 2, 3
END;
For more information about system defined types check the following link.
5) Data Dictionary
Using data dictionary wisely can facilitate your job easier in many places. Basically, it stores critical information about database objects, user information and dynamic performance metrics. There are two general categories of data dictionary views. One is static views that begins with USER, ALL, DBA, CDB and the other is dynamic performance views that begins with V$ and GV$. Dynamic performance views provide real time statistics such as how many sessions are open, which SQL is executing, memory usage etc. You can use DICTIONARY and DICT_COLUMNS views to get information about all dictionary views.
SELECT * FROM DICTIONARY;
SELECT * FROM DICT_COLUMNS;
For example, if you want to find all data dictionary views related to JSON. You can run a query such as this.
--Oracle 19C
SELECT * FROM dictionary where table_name like '%JSON%';
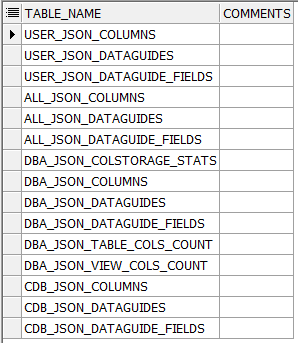
There are four different prefixes and the description of them show below.
| USER_ | Only shows the user’s own objects that selects the view. |
| ALL_ | Shows objects that the querying user has been granted privileges and own objects. |
| DBA_ | Shows all objects |
| CDB_ | CDB views involve all DBA views. |
Data dictionary is stored in the SYSTEM tablespace and it is always online when the database is open.
Below you can find some useful queries using the data dictionary.
--To find table name from the lowest or highest value of any column.
SELECT * FROM DBA_TAB_COL_STATISTICS
WHERE OWNER = 'USER' AND (UTL_RAW.CAST_TO_VARCHAR2(LOW_VALUE) LIKE '%DATA%' OR UTL_RAW.CAST_TO_VARCHAR2(HIGH_VALUE) LIKE '%DATA%');
--To find object name which contains a spesific code
SELECT * FROM DBA_SOURCE WHERE LOWER(TEXT) LIKE '%your code%';
--To list all columns of your table
SELECT LISTAGG(COLUMN_NAME, ',') WITHIN GROUP(ORDER BY COLUMN_ID) FROM USER_TAB_COLS WHERE TABLE_NAME = 'TABLE_NAME';
--Disk usage
select
df.tablespace_name "Tablespace",
totalusedspace "Used GB",
(df.totalspace - tu.totalusedspace) "Free GB",
df.totalspace "Total GB",
round(100 * ( (df.totalspace - tu.totalusedspace)/ df.totalspace)) "Pct. Free"
from
(select tablespace_name, round(sum(bytes) / (1024*1024*1024), 2) TotalSpace from dba_data_files group by tablespace_name) df,
(select round(sum(bytes)/(1024*1024*1024), 2) totalusedspace, tablespace_name from dba_segments group by tablespace_name) tu
where df.tablespace_name = tu.tablespace_name
order by 4 desc;
ORACLE_MAINTAINED field has been introduced in Oracle 12c. This is a useful field that species whether the user was created by Oracle-supplied scripts. For example, if you want to find only objects created by non-default users, instead of filter each user individually, you can use the following query.
SELECT * FROM ALL_OBJECTS
WHERE OWNER IN (SELECT USERNAME FROM ALL_USERS WHERE ORACLE_MAINTAINED = 'N');
Moreover, you can use SYS_CONTEXT built-in SQL function to display your session information.
SELECT
sys_context('USERENV', 'CURRENT_USER') usr,
sys_context('USERENV', 'AUTHENTICATION_METHOD') auth_method,
sys_context('USERENV', 'HOST') host,
sys_context('USERENV', 'DB_NAME') db_name,
sys_context('USERENV', 'INSTANCE_NAME') inst,
sys_context('USERENV', 'IP_ADDRESS') ip_addr,
sys_context('USERENV', 'SERVER_HOST') server_host,
sys_context('USERENV', 'SERVICE_NAME') service_name,
sys_context('USERENV', 'SID') sid,
sys_context('USERENV', 'TERMINAL') terminal,
sys_context('USERENV', 'OS_USER') os_user
FROM dual;
Bonus
In Oracle 11g and backwards, you cannot use upper queries predicate in inline views. It can be happened implicitly in query transformation (predicate pushdown). Oracle 12c introduce LATERAL inline view syntax. Hence, you can use this feature as shown in the following.
CREATE TABLE TEMP1
AS
SELECT * FROM DBA_OBJECTS;
SELECT
COUNT(*)
FROM TEMP1 T1,
(SELECT * FROM TEMP1 T2 WHERE OWNER = 'SYSTEM' AND T1.OBJECT_ID = T2.OBJECT_ID);
Error at line 1
ORA-00904: "T1"."OBJECT_ID": geçersiz belirleyici
As it can be seen from the above example, you cannot reference T1.OBJECT_ID predicate in the inline view instead you can use LATERAL syntax as of Oracle 12c.
SELECT
COUNT(*)
FROM TEMP1 T1 INNER JOIN LATERAL
(SELECT * FROM TEMP1 T2 WHERE OWNER = 'SYSTEM' AND T1.OBJECT_ID = T2.OBJECT_ID)
ON 1 = 1;
SELECT
COUNT(*)
FROM TEMP1 T1,
LATERAL (SELECT * FROM TEMP1 T2 WHERE OWNER = 'SYSTEM' AND T1.OBJECT_ID = T2.OBJECT_ID);
I hope you found this helpful. 🙂
If you are talking about life saving Oracle features, don’t forget the recycle bin – https://wordpress.com/post/dbajonblog.wordpress.com/1259
Thank you so much for your useful post